
An Introduction to Proteins
Proteins and what they do^
Proteins are very important molecules to all forms of life. They are one of four of life’s basic building blocks; the other three are carbohydrates (sugars), lipids (fats), and nucleic acids (DNA and RNA).Proteins make up about 15% of your body weight, and serve all kinds of functions. They can be part of structural elements in a cell on a small scale, or part of the fibers that make up your muscles on a larger scale. However, proteins do a lot more than just hold things together. Enzymes, for example, are a class of proteins that are essential for all kinds of reactions that occur in your body, from digestion of food to the replication of DNA. Other kinds of proteins include antibodies, which help your immune system fight off infections, and hormones, which send messages throughout your body. You may be wondering how these proteins in the body are related to dietary protein that you eat. In fact, they are both made up of the same basic materials, and when you eat dietary protein, your body recycles these materials and uses them to build all of the protein in your body. In this chapter you will learn how proteins are made and what they look like. In the final section, you will look at this process by using the huntingtin protein as an example. Before reading further, make sure you are familiar with the material in Introduction to DNA and Chromosomes.
How are proteins made?^

In order to learn how proteins are made you will have to familiarize yourself with the Central Dogma of molecular biology. The Central Dogma basically states that DNA provides the instructions for making RNA, and RNA then provides the instructions for making protein. The overall concept of protein synthesis is basic, but the details of this process are quite complex.

As we just learned in “An Introduction to DNA and Chromosomes,” DNA contains all of the instructions for life. It is present in each and every cell of the body, located in a compartment called the nucleus. DNA can be thought of as a blueprint to a house because it provides all of the instructions about the materials to be used and how it is to be built. Proteins can be thought of as some of the different materials used to build the house (wood, glass, bricks), as well as the people and devices that help put the house together. But before all this can happen, there must be a middleman between the DNA’s instructions and the actual protein. This middleman is called RNA.

RNA is actually rather similar to DNA. Just like DNA, it is made of nucleotide subunits that contain a sugar molecule, a phosphate group, and a nitrogenous base.

But unlike DNA, the RNA sugar molecule has an additional chemical group that makes it more reactive, but less stable, than DNA. The name RNA stands for ribonucleic acid, which comes from the name of the specific sugar molecule, ribose (remember that DNA has the sugar deoxyribose, which is why it is called deoxyribonucleic acid). Another difference is that while DNA is comprised of four bases – adenine (A), guanine (G), cytosine (C), and thymine (T) – RNA uses the first three, but substitutes the base uracil (U) for T.
While DNA is usually double-stranded, RNA is most often single-stranded (although there are exceptions). DNA never leaves the nucleus of complex cells, but RNA can be found both inside and outside of the nucleus. For a summary of these differences between DNA and RNA, see the table below.
Differences Between DNA and RNA
| DNA | RNA | |
| Sugar molecule | Deoxyribose | Ribose |
| Bases | A, G, C, and T | A, G, C, and U (uracil) |
| # of strands | Double-stranded | Single-stranded |
| Location | Nucleus | Nucleus or cytoplasm |

Now that we know more about RNA, we can explore the first half of the Central Dogma. The first step involves going from DNA to RNA and is called transcription. In the process of transcription, one strand of DNA is used as a template to build the RNA strand. Normally only a small section of the DNA is transcribed. The specific section to be transcribed usually makes up one gene. Remember how DNA is double-stranded and all wound up like a spiral staircase? Well, in order to be able to use the DNA as a template, it first has to be unwound and separated from its partner strand. You can think about this separation as unzipping a zipper, which can then be zipped up again later. So far, this process is very similar tao DNA replication. (For a review of DNA replication click here.) The major difference is that instead of making a complementary strand of DNA, a strand of RNA is made. Once the bases of the DNA template strand are exposed, RNA nucleotides can begin to match up with their complementary pairs. Just as in DNA replication, C pairs with G and G pairs with C. However, since RNA uses U instead of T, it will match A to T, and U to A.

Once the entire section has been transcribed, the RNA strand separates from the DNA template, and what is left is the RNA transcript.
The RNA strand that remains is called messenger RNA (mRNA). This name is fitting because mRNA acts as the messenger between DNA and protein. After a few subtractions and additions to the strand, the mRNA transcript can exit the nucleus. You are now ready to explore the second half of the Central Dogma: translation. Translation is the process by which mRNA is used to create proteins. At this stage, mRNA serves as the blueprint for a protein product. The process of going from RNA to protein is called translation because we are, in effect, changing languages. The basic subunit of DNA and RNA is the nucleotide, while the basic subunit of protein is the amino acid. The translation is from the language of RNA (nucleotides) to the language of protein (amino acids).

In order to complete this translation, some important helpers are needed. One of these helpers is the ribosome, a small organelle located in the cytoplasm of the cell.
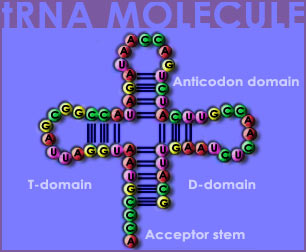
Another one of these helpers is transfer RNA (tRNA).

tRNA is made up of the same subunits as mRNA, but it has a very different function. tRNA can be thought of as the bilingual interpreter because it understands both the language of RNA and protein. One tRNA can bind to one of twenty different amino acids on one end, and to mRNA on the other end. tRNA binds to an mRNA codon by matching it to its own anticodon. Recall that a codon is simply a group of three bases. An anticodon is a sequence of three bases on the tRNA that is complementary to a codon on the mRNA (sometimes the anticodon is also referred to as just a codon). Each codon calls for a specific amino acid, although several different codons can call for the same amino acid. By being able to read a codon and match it up with the corresponding amino acid, tRNA plays an important role in translation.
Next we will discuss how we go from this one amino acid to the chain of amino acids that makes up a protein.
Now the different helpers must all work together to translate the mRNA into a protein. The ribosome has two main parts and the mRNA is held between them. The ribosome also has two binding sites. The first site, the A site, is where a new tRNA is accepted. At this point, the tRNA is bound to both its amino acid and the mRNA. This first tRNA is then pushed into the second binding site, the P site, pulling the mRNA along with it. P stands for peptide because this site is where the peptide bond is formed. A peptide bond is the link between two amino acids, and peptide is a word to describe two linked amino acids. (A chain of several linked amino acids is sometimes called an oligopeptide, a larger chain of amino acids is a polypeptide, and once the chain of amino acids is in its final shape it is called a protein.)
Once the first tRNA has been moved to the P site, the second tRNA can bind to the A site. The amino acid linked to the first tRNA is positioned close to the amino acid linked to the second tRNA, and a peptide bond is formed between them. The first tRNA can then release its amino acid, which is now linked to the amino acid on the second tRNA. The mRNA transcript is moved again, so that the second tRNA moves from the A site to the P site, and the first tRNA is moved out of the P site to the exit site, where it leaves the mRNA and ribosome. The process continues for each codon on the mRNA: a new tRNA binds to the codon matching its anticodon, attaches to the corresponding amino acid, and is moved into the A site of the ribosome. The growing amino acid chain is connected to the newest amino acid, and the tRNA is pushed into the P site and then out. For a pictorial description of translation, see figure 10a-c.

Figure P-10a

Figure P-10b

Figure P-10c
Once the entire mRNA transcript has been translated from nucleotide codons to a chain of amino acids, the polypeptide is cut free, and the ribosome-mRNA complex falls apart. The mRNA is soon degraded and the parts are recycled, and the ribosome goes on to translate other mRNA transcripts. We are left with the free amino acid chain, but we do not have a completed protein yet! You will find out how a protein is finished in the next section, part 3.
What do proteins look like?

We have already learned that proteins are made up of a chain of amino acids linked by peptide bonds. But what exactly is an amino acid? There are three main parts to each amino acid. The first part is the carboxylic acid group, typically written as “COOH” because it is made of one carbon (C) atom, two oxygen (O) atoms, and one hydrogen (H) atom. The second part is the amine group and is typically written “NH2” because it is made of one nitrogen (N) atom bound to two hydrogen atoms. These two groups are identical in all twenty amino acids, but it is the third group that is different in each one. This group is called the “R” group, where R stands for one of twenty possibilities of side chains. The different side chains are what give the amino acids different properties. For example, a side chain could be positively or negatively charged or attracted to or repelled by water. Amino acids that are attracted to water are called hydrophilic, or water loving, while amino acids that are repelled by water are called hydrophobic, or water fearing. The different properties of each side chain determine how the amino acids will interact with each other and with the surrounding environment. The carboxylic acid, the amine, the R group, and a single hydrogen atom are all bound to a central carbon atom to make an amino acid.

When two amino acids are linked together, the carboxylic acid group (COOH) of one amino acid connects to the amine group (NH2) of another amino acid. The new bond that is formed is called a peptide bond.

Now that we know more about the basic subunits of protein, we can learn more about their overall form. Proteins have four increasingly complex levels of structure. The first level, primary structure, describes the specific order, or sequence, of the amino acids. Remember that the order of amino acids comes directly from the DNA sequence from which it was transcribed. This chain of amino acids is basically what we are left with immediately following translation. Recall that the 4 letters of the DNA alphabet have been translated into the 20 letters of the protein alphabet. The primary structure also holds all of the information needed for forming the other three levels of structure.

A straight chain of amino acids is not the final form of the protein. In fact, proteins can have very complex shapes, and the final form of the protein is essential to its intended function. Perhaps you have heard of protein “folding.” Folding is the word used to describe the process by which the chain of amino acids is modified to reach its final form. After primary structure, the next level of complexity is called secondary structure. Secondary structure describes common folding patterns (often called “motifs”) seen in proteins. One type of secondary structure is the alpha helix. An alpha helix looks like a coil.

Another type of secondary structure is the beta sheet. A beta sheet looks kind of like a pleated skirt, or a piece of paper folded back and forth like a fan.

The reason why proteins fold in these characteristic ways has to do with the order of different types of amino acids. Remember how some amino acids are hydrophilic while others are hydrophobic? Well, depending on the type of environment where the protein ends up, it will fold so that its hydrophobic parts are hidden from water and its hydrophilic parts are facing water. In a watery environment, the hydrophilic amino acids will face out, while the hydrophobic amino acids will face inside the coil away from the water. Sometimes several secondary structure motifs will come together to form one bigger structure; this is called supersecondary structure. An example of supersecondary structure is when a bunch of alpha helices or beta sheets form a ring, called a barrel. Barrels are often found in the cell membrane and act as pores.
To review the secondary structure motifs, click on the buttons below to highlight alpha helices and beta sheets.

The next level of complexity is called tertiary structure. Tertiary structure describes the overall three-dimensional structure of a single folded amino acid chain. This level includes the different kinds of bonds that hold the protein in its three-dimensional shape. Sometimes, tertiary structure is the highest level of complexity seen in a protein. However, often a fourth level is needed to describe the final protein’s structure; this level is called quaternary structure. When a protein is made up of more than one polypeptide chain, the complete protein with all of the subunits together makes up the quaternary structure. The subunits can all be copies of the same polypeptide, or they can be different polypeptides linked together.
Example: The huntingtin protein
Now that you have the basic idea of how a gene becomes a protein, we are going to follow the Huntington gene on its journey to becoming the huntingtin protein. Our story begins in the nucleus, when we zoom in on a particular section of chromosome 4. This section is where the DNA sequence known as the Huntington gene is located. The gene is actually quite long (180 kb), so it would take a lot of space to write out. Just to give you an idea, here are the first 600 bases:
1 TTGCTGTGTG AGGCAGAACC TGCGGGGGCA GGGGCGGGCT GGTTCCCTGG CCAGCCATTG 61 GCAGAGTCCG CAGGCTAGGG CTGTCAATCA TGCTGGCCGG CGTGGCCCCG CCTCCGCCGG 121 CGCGGCCCCG CCTCCGCCGG CGCACGTCTG GGACGCAAGG CGCCGTGGGG GCTGCCGGGA 181 CGGGTCCAAG ATGGACGGCC GCTCAGGTTC TGCTTTTACC TGCGGCCCAG AGCCCCATTC 241 ATTGCCCCGG TGCTGAGCGG CGCCGCGAGT CGGCCCGAGG CCTCCGGGGA CTGCCGTGCC 301 GGGCGGGAGA CCGCCATGGC GACCCTGGAA AAGCTGATGA AGGCCTTCGA GTCCCTCAAG 361 TCCTTCCAGC AGCAGCAGCA GCAGCAGCAG CAGCAGCAGC AGCAGCAGCA GCAGCAGCAG 421 CAGCAGCAGC AACAGCCGCC ACCGCCGCCG CCGCCGCCGC CGCCTCCTCA GCTTCCTCAG 481 CCGCCGCCGC AGGCACAGCC GCTGCTGCCT CAGCCGCAGC CGCCCCCGCC GCCGCCCCCG 541 CCGCCACCCG GCCCGGCTGT GGCTGAGGAG CCGCTGCACC GACCAAAGAA AGAACTTTCA
Remember that there are only four letters in the DNA alphabet: A, C, G, and T. The different combinations of these four letters comprise the instructions for everything that occurs in your body. In our case, the instructions in the Huntington gene are to create the huntingtin protein. You may have noticed that a certain section of the genetic code has been highlighted. Do you notice anything in particular about this section? In the highlighted section, the bases C-A-G are repeated a number of times. Everyone has a CAG repeat in the Huntington gene, but the number of repeats is different for each person. In this case, there are only 21 repeats, which falls within the normal range of repeats, so we would refer to this as the non-HD allele. Remember that everyone has two copies (alleles) of the Huntington gene. Having only one copy with too many CAG repeats will result in a person getting HD.
Let’s get back to our journey. When the signal arrives indicating that more huntingtin protein is needed, the process of transcription begins. The DNA section containing the Huntington gene begins to uncoil, and the two complementary strands are separated, exposing the bases. Now the RNA nucleotides begin to fly in, matching up with their base pairs on the DNA. Let’s take a look at how this would work, using the DNA sequence for the first 30 bases:
DNA: TTGCTGTGTG AGGCAGAACC TGCGGGGGCA…
Now we must match each DNA base with the complementary RNA base. Recall that T matches with A, G matches with C, and C matches with G. What does A match with? Be careful – remember that RNA does not use T, it instead uses U! The correctly matched bases would be ordered as follows:
DNA: TTGCTGTGTG AGGCAGAACC TGCGGGGGCA...
mRNA: AACGACACAC UCCGUCUUGG ACGCCCCCGU...
This process must be carried out for the entire DNA sequence comprising the gene; we’ve only matched the first 30 bases. Once each base is matched with its complement, the mRNA transcript is formed. Before it exits the nucleus, it may encounter some changes such as the removal of unnecessary sections.
We are finished with transcription, so we exit the nucleus and enter the main part of the cell: the cytoplasm. The mRNA transcript must now meet up with a ribosome to get the process of translation going. The two parts of the ribosome clamp down on the beginning of the mRNA transcript, and we are just about ready to start. What do we need to translate from the language of RNA to the language of protein? Our interpreters, tRNA! Different tRNAs fly by, reading the mRNA bases in groups of three; remember that these groups of three are called codons. Each codon translates to one amino acid. If a tRNA finds a codon on the mRNA with a sequence that is complementary to its own anticodon, we’re in business! When a tRNA has its amino acid on one end and a matching codon on the other, the tRNA binds to the ribosome. Let’s see how this would go for the first 30 bases of the mRNA that we transcribed. Here is the beginning of the mRNA transcript:
mRNA: AACGACACAC UCCGUCUUGG ACGCCCCCGU…
Since the tRNAs read the bases as codons, let’s separate the transcript into groups of three bases:
mRNA: AAC GAC ACA CUC CGU CUU GGA CGC CCC CGU…
Now each mRNA codon must be matched up with a tRNA with a complementary anticodon. Remembering that A and U pair with each other and G and C pair with each other, we can write the correct order of tRNA anticodons:
mRNA: AAC GAC ACA CUC CGU CUU GGA CGC CCC CGU…
tRNA: UUG CUG UGU GAG GCA GAA CCU GCG GGG GCA...
Each of these three-letter “words” translates to one amino acid. The tRNA translates the codon into the correct amino acid because it can only bind to one of each. When we humans want to translate, we use a chart such as the one found here . The resulting string of amino acids is as follows:
{kind=link}
tRNA: UUG CUG UGU GAG GCA GAA CCU GCG GGG GCA…
Protein: Leu Leu Cys Glu Ala Glu Pro Ala Gly Ala…
The way the amino acids are written here is in their three-letter abbreviations. Each amino acid also has a one-letter abbreviation. The beginning of our protein written with the one-letter abbreviations is as follows: LLCEAEPAGA. When we get to the section with the CAG repeats, we will find that the codon CAG translates to the amino acid glutamine (abbreviated as Gln or Q). The many repeated CAG codons will translate into a string of glutamines in the resulting protein, which is why HD is also known as a polyglutamine or polyQ disease (“poly” means many). (For more information on polyglutamine diseases, click here.)

The mRNA transcript will continue going through the ribosome as each new tRNA binds to the matching codon with its corresponding amino acid. A peptide bond will form between the growing amino acid chain and the latest amino acid until all of the codons have been translated and we have our complete polypeptide. We are now left with the full sequence of amino acids, or the primary structure.

While the three-dimensional structure has not been completely determined, we do know what at least part of the protein looks like. The huntingtin protein is comprised mostly of “HEAT” motifs. These HEAT motifs have a characteristic pattern and often appear repeated together, as they do in the huntingtin protein about ten times. An example of what a section of the huntingtin protein containing these HEAT repeat sequences might look like is shown on the left.
Do you notice any familiar secondary structure motifs? There are many alpha helices in the HEAT motif of the huntingtin protein. The tertiary structure of this section describes the relationship in space between each alpha helix. As you can see, this section has two polypeptide strings; the quaternary structure of just this section would include both polypeptides and their relationship to one another. The entire huntingtin protein is a very large protein made from many polypeptide strings, so the overall quaternary structure would be the whole protein with all of the different polypeptides together.
It is important to note that this is an example of a “normal” huntingtin protein, one that originated from a DNA sequence that did not have enough CAG repeats to result in HD. If the DNA sequence had 40 or more CAG repeats, then the transcribed mRNA sequence would have had 40 or more GUC repeats. The translating tRNA would match each of these GUC codons with the anticodon CAG, corresponding to the amino acid glutamine. So, the resulting protein would have 40 or more glutamines (depending on the actual number of repeats in the DNA). This change in the sequence would affect how the protein folds. Since the way a protein folds determines the final shape of the protein, and the shape of the protein determines the function, this HD protein will not function properly, and the person will develop Huntington’s disease.
We can now begin to understand how the number of CAG repeats determines whether or not a person will develop HD. We can think of 35 repeats as a threshold, where, up to this number of repeats, the protein can still fold well enough to get its job done. Any more than 35 repeats—and certainly more than 40 repeats—changes the way the protein folds so that it cannot function normally. When a protein’s ability to fold is changed, there are two possibilities for what happens to its function. The protein can simply stop working altogether (this is called “loss of function”) or it can acquire a new kind of function (this is called “gain of function”). If the protein gains a function, it is possible to be helpful but more likely it is harmful. A harmful new function is often called “toxic gain of function.” Current research suggests that the protein resulting from the HD allele has a toxic gain of function. This new function contributes to the development of HD.
To summarize, 35 or fewer CAG repeats in the Huntington gene allows the resulting huntingtin protein to fold normally. The normal shape allows normal function and the person with two normally folded huntingtin proteins will not develop HD. A Huntington gene with 40 or more CAG repeats will result in an improperly folded huntingtin protein. The abnormal shape resulting from too many glutamines in the protein will prevent normal functioning of the huntingtin protein. The change of function in one abnormal huntingtin protein is enough to lead to the development of HD.
For further reading
- Biology-Online.org. “Protein Synthesis.” http://www.biology-online.org/1/6_protein_synthesis.htm. This is an excellent overview of protein synthesis and is easy to understand.
- Friedli, George-Louis. http://www.friedli.com/herbs/phytochem/proteins.html. This is a fairly difficult overview of amino acids and protein structure.
-K. Taub, 1-29-06